



Analyzing Business Intelligence (BI) and Analytics job market in Tableau
⏱ Время чтения текста – 13 минут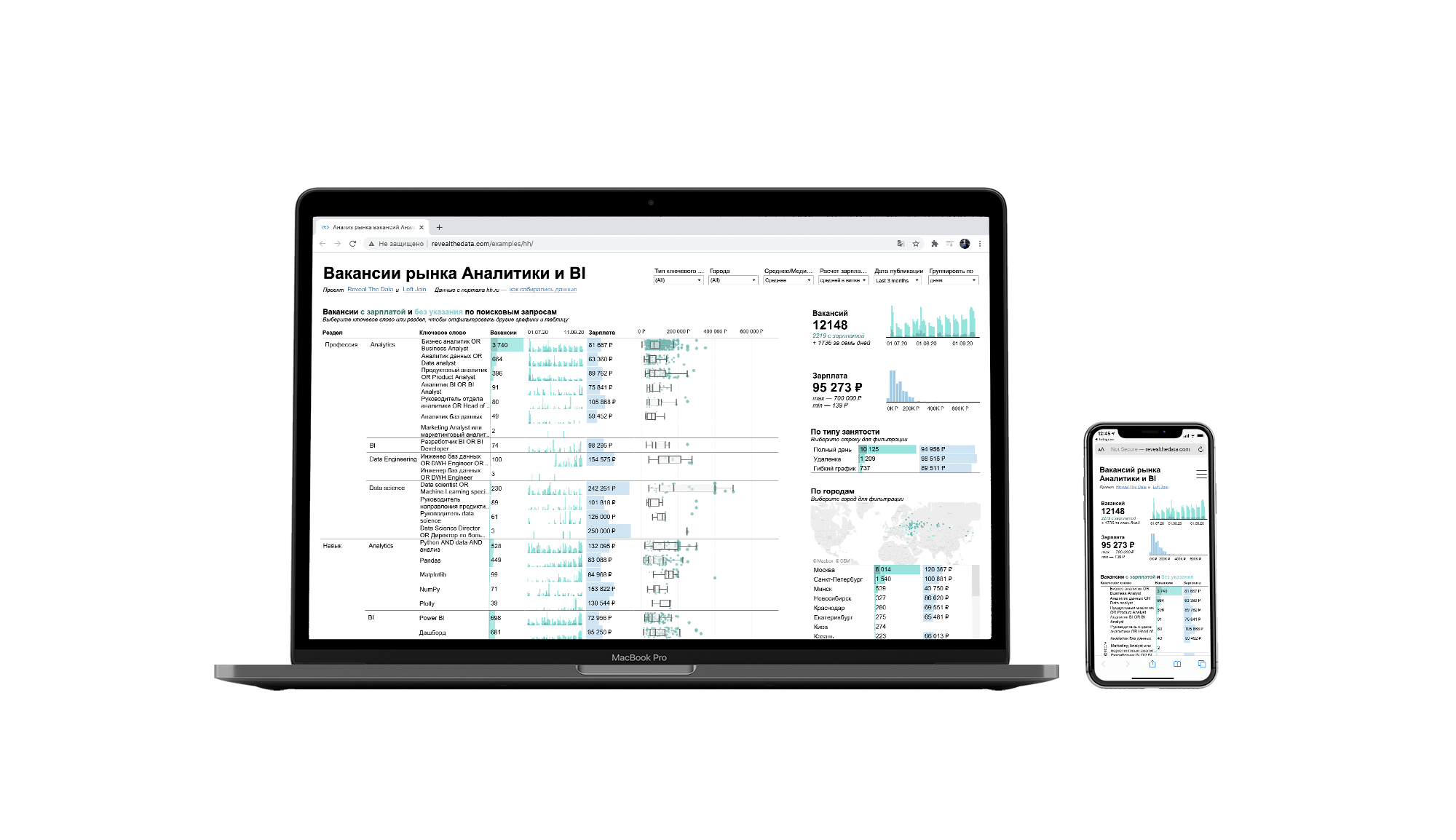
According to the SimilarWeb rating, hh.ru is the third among the most popular job search websites in the world. In one of the conversations with Roman Bunin, we came up with the idea of making a common project and collect data using the HeadHunter API for later analysis and visualization in Tableau Public. Our goal was to understand the dependency between salary and skills specified in a job posting and compare how things are in Moscow, Saint Petersburg, and other regions.
Data Collection Process
Our scheme is based on fetching a brief job description, returned by the GET /vacancies method. According to the structure we need to create the following columns: vacancy type, id, vacancy rate (‘premium’), pre-employment testing (‘has_test’), company address, salary, work schedule, and so forth. We created a table using the following CREATE query down below:
Query for creating the vacancies_short table in ClickHouse
CREATE TABLE headhunter.vacancies_short
(
`added_at` DateTime,
`query_string` String,
`type` String,
`level` String,
`direction` String,
`vacancy_id` UInt64,
`premium` UInt8,
`has_test` UInt8,
`response_url` String,
`address_city` String,
`address_street` String,
`address_building` String,
`address_description` String,
`address_lat` String,
`address_lng` String,
`address_raw` String,
`address_metro_stations` String,
`alternate_url` String,
`apply_alternate_url` String,
`department_id` String,
`department_name` String,
`salary_from` Nullable(Float64),
`salary_to` Nullable(Float64),
`salary_currency` String,
`salary_gross` Nullable(UInt8),
`name` String,
`insider_interview_id` Nullable(UInt64),
`insider_interview_url` String,
`area_url` String,
`area_id` UInt64,
`area_name` String,
`url` String,
`published_at` DateTime,
`employer_url` String,
`employer_alternate_url` String,
`employer_logo_urls_90` String,
`employer_logo_urls_240` String,
`employer_logo_urls_original` String,
`employer_name` String,
`employer_id` UInt64,
`response_letter_required` UInt8,
`type_id` String,
`type_name` String,
`archived` UInt8,
`schedule_id` Nullable(String)
)
ENGINE = ReplacingMergeTree
ORDER BY vacancy_idThe first script collects data from the HeadHunter website through API and inserts to our Database using the following libraries:
import requests
from clickhouse_driver import Client
from datetime import datetime
import pandas as pd
import reNext, we create a DataFrame and connect to the Database in ClickHouse:
queries = pd.read_csv('hh_data.csv')
client = Client(host='1.234.567.890', user='default', password='', port='9000', database='headhunter')The queries table stores a list of our search queries, having the following columns: query type, level, career field, and search phrase. The last column contains logical operators, for instance, we can get more results by putting logical ANDs between “Python”, “data” and “analysis”.

The search results may not always match the expectations, chiefs, marketers, and administrators can accidentally get into our database. To prevent this, we will write a function named check_name(name), it will accept a vacancy name and return a boolean value, depending on the match.
def check_name(name):
bad_names = [r'курьер', r'грузчик', r'врач', r'менеджер по закупу',
r'менеджер по продажам', r'оператор', r'повар', r'продавец',
r'директор магазина', r'директор по продажам', r'директор по маркетингу',
r'кабельщик', r'начальник отдела продаж', r'заместитель', r'администратор магазина',
r'категорийный', r'аудитор', r'юрист', r'контент', r'супервайзер', r'стажер-ученик',
r'су-шеф', r'маркетолог$', r'региональный', r'ревизор', r'экономист', r'ветеринар',
r'торговый', r'клиентский', r'начальник цеха', r'территориальный', r'переводчик',
r'маркетолог /', r'маркетолог по']
for item in bad_names:
if re.match(item, name):
return TrueMoving further, we need to create a while loop to collect data non-stop. Iterate over the Dataframe queries selecting the type, level, field, and search phrase columns. Send a GET request using a keyword to get the number of pages. Then we loop through the number of pages sending the same requests and populating vacancies_from_response with job descriptions. In the per_page parameter we specified 10, this is the max limit for the HH API. Since we didn’t pass any value to the area field, the results are collected worldwide.
while True:
for query_type, level, direction, query_string in zip(queries['Query Type'], queries['Level'], queries['Career Field'], queries['Seach Phrase']):
print(f'seach phrase: {query_string}')
url = 'https://api.hh.ru/vacancies'
par = {'text': query_string, 'per_page':'10', 'page':0}
r = requests.get(url, params=par).json()
added_at = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
pages = r['pages']
found = r['found']
vacancies_from_response = []
for i in range(0, pages + 1):
par = {'text': query_string, 'per_page':'10', 'page':i}
r = requests.get(url, params=par).json()
try:
vacancies_from_response.append(r['items'])
except Exception as E:
continueCreate a for loop to escape duplicate rows in our table. First, send a query to the database, verifying whether there is a vacancy with the same id and search phrase. If the verification was successful we then
pass the job title to check_name() and move on to the next one.
for item in vacancies_from_response:
for vacancy in item:
if client.execute(f"SELECT count(1) FROM vacancies_short WHERE vacancy_id={vacancy['id']} AND query_string='{query_string}'")[0][0] == 0:
name = vacancy['name'].replace("'","").replace('"','')
if check_name(name):
continueNow we need to extract all the necessary data from a job description. The table will contain empty cells, since some data may be missing.
View the code for extracting job description data
vacancy_id = vacancy['id']
is_premium = int(vacancy['premium'])
has_test = int(vacancy['has_test'])
response_url = vacancy['response_url']
try:
address_city = vacancy['address']['city']
address_street = vacancy['address']['street']
address_building = vacancy['address']['building']
address_description = vacancy['address']['description']
address_lat = vacancy['address']['lat']
address_lng = vacancy['address']['lng']
address_raw = vacancy['address']['raw']
address_metro_stations = str(vacancy['address']['metro_stations']).replace("'",'"')
except TypeError:
address_city = ""
address_street = ""
address_building = ""
address_description = ""
address_lat = ""
address_lng = ""
address_raw = ""
address_metro_stations = ""
alternate_url = vacancy['alternate_url']
apply_alternate_url = vacancy['apply_alternate_url']
try:
department_id = vacancy['department']['id']
except TypeError as E:
department_id = ""
try:
department_name = vacancy['department']['name']
except TypeError as E:
department_name = ""
try:
salary_from = vacancy['salary']['from']
except TypeError as E:
salary_from = "cast(Null as Nullable(UInt64))"
try:
salary_to = vacancy['salary']['to']
except TypeError as E:
salary_to = "cast(Null as Nullable(UInt64))"
try:
salary_currency = vacancy['salary']['currency']
except TypeError as E:
salary_currency = ""
try:
salary_gross = int(vacancy['salary']['gross'])
except TypeError as E:
salary_gross = "cast(Null as Nullable(UInt8))"
try:
insider_interview_id = vacancy['insider_interview']['id']
except TypeError:
insider_interview_id = "cast(Null as Nullable(UInt64))"
try:
insider_interview_url = vacancy['insider_interview']['url']
except TypeError:
insider_interview_url = ""
area_url = vacancy['area']['url']
area_id = vacancy['area']['id']
area_name = vacancy['area']['name']
url = vacancy['url']
published_at = vacancy['published_at']
published_at = datetime.strptime(published_at,'%Y-%m-%dT%H:%M:%S%z').strftime('%Y-%m-%d %H:%M:%S')
try:
employer_url = vacancy['employer']['url']
except Exception as E:
print(E)
employer_url = ""
try:
employer_alternate_url = vacancy['employer']['alternate_url']
except Exception as E:
print(E)
employer_alternate_url = ""
try:
employer_logo_urls_90 = vacancy['employer']['logo_urls']['90']
employer_logo_urls_240 = vacancy['employer']['logo_urls']['240']
employer_logo_urls_original = vacancy['employer']['logo_urls']['original']
except Exception as E:
print(E)
employer_logo_urls_90 = ""
employer_logo_urls_240 = ""
employer_logo_urls_original = ""
employer_name = vacancy['employer']['name'].replace("'","").replace('"','')
try:
employer_id = vacancy['employer']['id']
except Exception as E:
print(E)
response_letter_required = int(vacancy['response_letter_required'])
type_id = vacancy['type']['id']
type_name = vacancy['type']['name']
is_archived = int(vacancy['archived'])The last field is the work schedule. If there is mentioned a fly-in-fly-out method, these kinds of job postings will be skipped.
try:
schedule = vacancy['schedule']['id']
except Exception as E:
print(E)
schedule = ''"
if schedule == 'flyInFlyOut':
continueNext, we create a list of obtained variables, replacing None values with empty strings to escape errors with Clickhouse and insert them into the table.
vacancies_short_list = [added_at, query_string, query_type, level, direction, vacancy_id, is_premium, has_test, response_url, address_city, address_street, address_building, address_description, address_lat, address_lng, address_raw, address_metro_stations, alternate_url, apply_alternate_url, department_id, department_name,
salary_from, salary_to, salary_currency, salary_gross, insider_interview_id, insider_interview_url, area_url, area_name, url, published_at, employer_url, employer_logo_urls_90, employer_logo_urls_240, employer_name, employer_id, response_letter_required, type_id, type_name, is_archived, schedule]
for index, item in enumerate(vacancies_short_list):
if item is None:
vacancies_short_list[index] = ""
tuple_to_insert = tuple(vacancies_short_list)
print(tuple_to_insert)
client.execute(f'INSERT INTO vacancies_short VALUES {tuple_to_insert}')Connecting Tableau to the data source
Unfortunately, we can’t work with databases in Tableau Public, that’s why we decided to connect our Clickhouse Database to Google Sheets. With this in mind, we picked the following libraries: gspread and oauth2client for accessing Google Spreadsheets API, and schedule for task scheduling.
Refer to our previous article where we used Google Spreadseets API for “Collecting Data on Ad Campaigns from VK.com”
import schedule
from clickhouse_driver import Client
import gspread
import pandas as pd
from oauth2client.service_account import ServiceAccountCredentials
from datetime import datetime
scope = ['https://spreadsheets.google.com/feeds', 'https://www.googleapis.com/auth/drive']
client = Client(host='54.227.137.142', user='default', password='', port='9000', database='headhunter')
creds = ServiceAccountCredentials.from_json_keyfile_name('credentials.json', scope)
gc = gspread.authorize(creds)The update_sheet() function will transfer all data from Clickhouse to a Google Sheets table:
def update_sheet():
print('Updating cell at', datetime.now())
columns = []
for item in client.execute('describe table headhunter.vacancies_short'):
columns.append(item[0])
vacancies = client.execute('SELECT * FROM headhunter.vacancies_short')
df_vacancies = pd.DataFrame(vacancies, columns=columns)
df_vacancies.to_csv('vacancies_short.csv', index=False)
content = open('vacancies_short.csv', 'r').read()
gc.import_csv('1ZWS2kqraPa4i72hzp0noU02SrYVo0teD7KZ0c3hl-UI', content.encode('utf-8'))Using schedule to run our function every day at 1:00 PM (UTC):
schedule.every().day.at("13:00").do(update_sheet)
while True:
schedule.run_pending()What’s the final point?
Roman created an informative dashboard based on this data.

And made a youtube video with a detailed explanation of the dashboard features.
Key Insights
- Data Analysts specializing in BI are most in-demand in the job market since the highest number of search results were returned with this query. However, the average salary is higher in Product Analyst and BI-analyst openings.
- Most of the postings were found In Moscow, where the average salary is 10-30K RUB higher than in Saint Petersburg and 30-40K higher than in other regions.
- Top highly paid positions: Head of Analytics (110K RUB per month on avg.), Database Engineer (138K RUB per month), and Head of Machine Learning (250K RUB per month).
- The most useful skills to have are a solid knowledge of Python with Pandas and Numpy, Tableau, Power BI, ETL, and Spark. Most of the posings found contained these requirements and were highly paid than any others. For Python programmers, it’s more valuable to have expertise with Matplotlib than Plotly.
View the code on GitHub