



Sentiment analysis of Russians on Constitutional Amendments
⏱ Время чтения текста – 11 минутIn today’s article, we are going to use public data from vk.com to interpret and classify users’ attitudes about the 2020 amendments to the Constitution of Russia.
API Overview
First off, we need to receive data using the newsfeed.search method, this method allows us to get up to one thousand of the latest posts from the news feed by keyword.
The response data contains different fields, like post ids, user or community ids, text data, likes count, comments, apps, geolocation, and many more. We are only needed ids and text data.
Some expanded information about the author will also be useful for our analysis, this includes city, gender, age, and can be received with the users.get method.
Create Clickhouse Tables
The received data should be stored somewhere, we chose to use ClickHouse, an open-source column-oriented DBMS. Let’s create two tables to store users and their posts. The first table will be populated with ids and text data, the second one will hold user data, such as their ids, age, and city. The ReplacingMergeTree () engine will remove duplicates in our tables.
The article assumes that you’re familiar with how to install ClickHouse on AWS, create external dictionaries and materialized views
CREATE TABLE vk_posts(
post_id UInt64,
post_date DateTime,
owner_id UInt64,
from_id UInt64,
text String
) ENGINE ReplacingMergeTree()
ORDER BY post_date
CREATE TABLE vk_users(
user_id UInt64,
user_sex Nullable(UInt8),
user_city String,
user_age Nullable(UInt16)
) ENGINE ReplacingMergeTree()
ORDER BY user_idCollecting user posts with the VK API
Let’s get to writing our script, import the libraries, and create several variables with constant values:
If you don’t have an access token yet and want to create one, refer to this step by step guide: “Collecting Data on Ad Campaigns from VK.com”
from clickhouse_driver import Client
from datetime import datetime
import requests
import pandas as pd
import time
token = 'your_token'
version = 5.103
client = Client(host='ec1-23-456-789-1011.us-east-2.compute.amazonaws.com', user='default', password='', port='9000', database='default')
data_list = []
start_from = 0
query_string = 'конституция' #constitutionDefine the get_and_insert_info_by_user function that will receive a list of user ids and expanded information about them, and send it to the vk_users table. Since the user_ids parameter takes a list as a string object, we need to change the structure and omit the square brackets.
Most users prefer to conceal their gender, age, and city. In such cases, we need to use Nullable values. To obtain user age we need to subtract the birth year from the current year, if the birth year is missing we can check it using the regular expression.
get_and_insert_info_by_user() function
def get_and_insert_info_by_user(users):
try:
r = requests.get('https://api.vk.com/method/users.get', params={
'access_token':token,
'v':version,
'user_ids':str(users)[1:-2],
'fields':'sex, city, bdate'
}).json()['response']
for user in r:
user_list = []
user_list.append(user['id'])
if client.execute(f"SELECT count(1) FROM vk_users where user_id={user['id']}")[0][0] == 0:
print(user['id'])
try:
user_list.append(user['sex'])
except Exception:
user_list.append('cast(Null as Nullable(UInt8))')
try:
user_list.append(user['city']['title'])
except Exception:
user_list.append('')
try:
now = datetime.now()
year = item.split('.')[-1]
if re.match(r'\d\d\d\d', year):
age = now.year - int(year)
user_list.append(age)
except Exception:
user_list.append('cast(Null as Nullable(UInt16))')
user_insert_tuple = tuple(user_list)
client.execute(f'INSERT INTO vk_users VALUES {user_insert_tuple}')
except KeyError:
pass
Our script will work in a while loop to constantly update data, as we can only receive a thousand of the latest data points.The newsfeed.search method returns 200 posts per call, so we need to invoke it five times to collect all the posts.
While loop to collect new posts
while True:
for i in range(5):
r = requests.get('https://api.vk.com/method/newsfeed.search', params={
'access_token':token,
'v':version,
'q':query_string,
'count':200,
'start_from': start_from
})
data_list.append(r.json()['response'])
try:
start_from = r.json()['response']['next_from']
except KeyError:
passThe data we received can be parsed, VK users always have a positive id, while for communities it’s negative. We need only users data for our analysis, where from_id > 0. The next step is to check whether a post contains any text data or not. Finally, we will collect and store unique entries by user id. Pause the script after each iteration for 180 seconds to wait for new user posts and not violate the VK API rules.
Adding new data to Clickhouse
user_ids = []
for data in data_list:
for data_item in data['items']:
if data_item['from_id'] > 0:
post_list = []
if not data_item['text']:
continue
if client.execute(f"SELECT count(1) FROM vk_posts WHERE post_id={data_item['id']} AND from_id={data_item['from_id']}")[0][0] == 0:
user_ids.append(data_item['from_id'])
date = datetime.fromtimestamp(data_item['date'])
date = datetime.strftime(date, '%Y-%m-%d %H:%M:%S')
post_list.append(date)
post_list.append(data_item['id'])
post_list.append(data_item['owner_id'])
post_list.append(data_item['from_id'])
post_list.append(data_item['text'].replace("'","").replace('"','').replace("\n",""))
post_list.append(query_string)
post_tuple = tuple(post_list)
print(post_list)
try:
client.execute(f'INSERT INTO vk_posts VALUES {post_tuple}')
except Exception as E:
print('!!!!! try to insert into vk_post but got', E)
try:
get_and_insert_info_by_user(user_ids)
except Exception as E:
print("Try to insert user list:", user_ids, "but got:", E)
time.sleep(180)Dostoevsky for sentiment analysis
For one week our script collected almost 20000 posts from VK users that mention the keyword “constitution” (or “конституция” in Russian). It’s time to write our second script for data analysis and visualization. First, create a DataFrame with the data received, and evaluate the sentiment of each post, identifying whether it’s positive, negative, or neutral. We are going to use the Dostoevsky library to analyze the emotion behind a text.
from dostoevsky.tokenization import RegexTokenizer
from dostoevsky.models import FastTextSocialNetworkModel
from clickhouse_driver import Client
import pandas as pd
client = Client(host='ec1-23-456-789-1011.us-east-2.compute.amazonaws.com', user='default', password='', port='9000', database='default')Assign all the contents of our table to the vk_posts variable with a simple query. Iterate through all the posts, select those with text data and populate our DataFrame.
vk_posts = client.execute('SELECT * FROM vk_posts')
list_of_posts = []
list_of_ids = []
for post in vk_posts:
if str(post[-2]).replace(" ", ""):
list_of_posts.append(str(post[-2]).replace("\n",""))
list_of_ids.append(int(post[2]))
df_posts = pd.DataFrame()
df_posts['post'] = list_of_posts
df_posts['id'] = list_of_idsInstantiate our model and iterate through the posts to evaluate the sentiment of each entry.
tokenizer = RegexTokenizer()
model = FastTextSocialNetworkModel(tokenizer=tokenizer)
sentiment_list = []
results = model.predict(list_of_posts, k=2)
for sentiment in results:
sentiment_list.append(sentiment)Add several boolean columns to our DataFrame that will reflect whether it’s a positive, negative, or neutral post.
neutral_list = []
negative_list = []
positive_list = []
speech_list = []
skip_list = []
for sentiment in sentiment_list:
neutral = sentiment.get('neutral')
negative = sentiment.get('negative')
positive = sentiment.get('positive')
if neutral is None:
neutral_list.append(0)
else:
neutral_list.append(sentiment.get('neutral'))
if negative is None:
negative_list.append(0)
else:
negative_list.append(sentiment.get('negative'))
if positive is None:
positive_list.append(0)
else:
positive_list.append(sentiment.get('positive'))
df_posts['neutral'] = neutral_list
df_posts['negative'] = negative_list
df_posts['positive'] = positive_listThat’s how the DataFrame looks now:

Let’s examine the most negative posts:
df_posts[df_posts.negative > 0.9]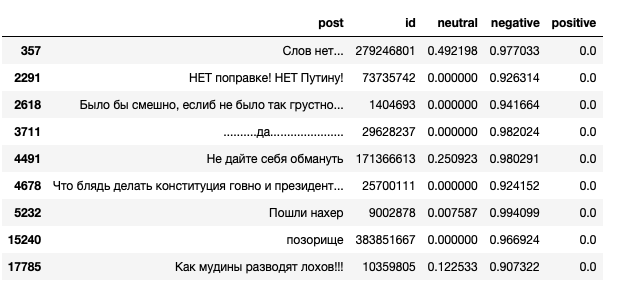
Now, let’s add data about the authors of these posts by merging two tables together on the id column.
vk_users = client.execute('SELECT * FROM vk_users')
vk_user_ids_list = []
vk_user_sex_list = []
vk_user_city_list = []
vk_user_age_list = []
for user in vk_users:
vk_user_ids_list.append(user[0])
vk_user_sex_list.append(user[1])
vk_user_city_list.append(user[2])
vk_user_age_list.append(user[3])
df_users = pd.DataFrame()
df_users['id'] = vk_user_ids_list
df_users['sex'] = vk_user_sex_list
df_users['city'] = vk_user_city_list
df_users['age'] = vk_user_age_list
df = df_posts.merge(df_users, on='id')And the table now looks the following:
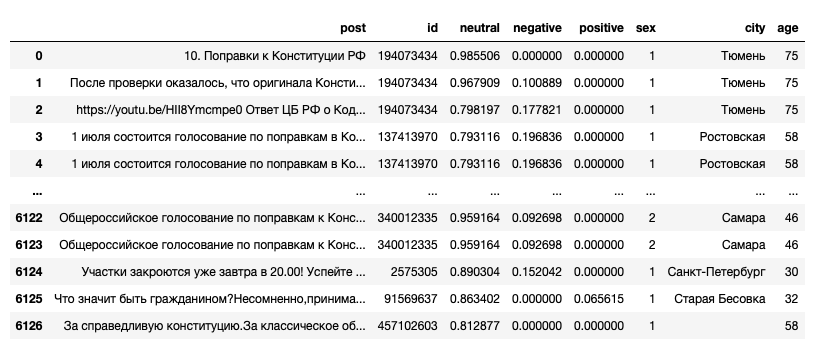
Analysing data with Plotly
Check out our previous article on data visualization with Plotly: “Building an interactive waterfall chart in Python”
Let’s find the percentage of posts for each group: positive, negative, neutral. Iterate through these three columns and calculate the values more than zero for each data point. Then do the same for different age categories and gender.
According to our chart, 45% of recent user posts relevant to the keyword “constitution” have a negative meaning, while the other 52% are neutral. Later it’ll be known how different the Internet opinions from the voting results.
It’s noticeable that among the men audience the proportion of positive posts is less than 2%, while for women it’s 3.5%. However, the number of negative posts for each group is almost the same, 47% and 43% respectively.
According to our analysis, posts made by younger audiences between 18-25 years have more positive sentiment, which is 6%. While users under 18 years leave mostly negative posts, this may be because most users under the age of 18 prefer to hide their real age, this makes it difficult to obtain accurate data for such a group.
The proportion of negative posts is almost equal for all groups and accounts for 44%.
As you can see, the data is distributed equally in all three charts. This means that half of all posts relevant to the keyword “constitution” and made by VK users over the past week mostly have a negative sentiment.

























