Today we are going to talk about BI-platform Looker, on which I managed to work in 2019.
Here is the short content of the article for convenient and fast navigation:
- What is Looker?
- Which DBMS you can connect to via Looker and how?
- Building of Looker ML data model
- Explore Mode (data research on the model built)
- Building of reports and their saving in Look
- Examples of dashboards in Looker
What is Looker?
Creators of Looker position it as a software of business intelligence class and big data analytics platform, that helps to research, analyze and share business analytics in real time mode.
Looker — is a really convenient tool and one of a few BI products, that allows to work with pre-set data cubes in a real-time mode (actually, relational tables that are described in Look ML-model).
An engineer, working with Looker, needs to describe a data model on Look ML language (it’s something between CSS and SQL), publish this data model and then set reporting and dashboards.
Look ML itself is pretty simple, the nexus between the data objects are set by a data-engineer, which consequently allows to use the data without knowledge of SQL language (to be precise: Looker engine generates the code in SQL language itself on user’s behalf).
Just recently, in June 2019, Google announced acquisition of Looker platform for $2.6 billion.
Which DBMS you can connect to via Looker and how?
The selection of DBMS that Looker is working with is pretty wide. You can see the various connections on the screen shot below as of October, 2019:
Available DBMS for connection
You can easily set a connection to the database via web-interface:
Web-interface of connection to DBMS
With regard to connections to databases, I’d like to highlight the following two facts: first of all, unfortunately, Clickhouse support from Yandex is currently missing (as well as in the foreseeable future). Most likely, the support won’t appear, considering the fact that Looker was acquired by a competitor, Google.
updated: Actually, Looker supports Clickhouse from the December 2019
The second nuisance is that you can’t build one data model, that would apply to different DBMS. There is no inbuilt storage in Looker, that could combine the results of query (unlike the same Redash).
It means, that analytical architecture should be built within one DBMS (preferably with high action speed or on aggregated data).
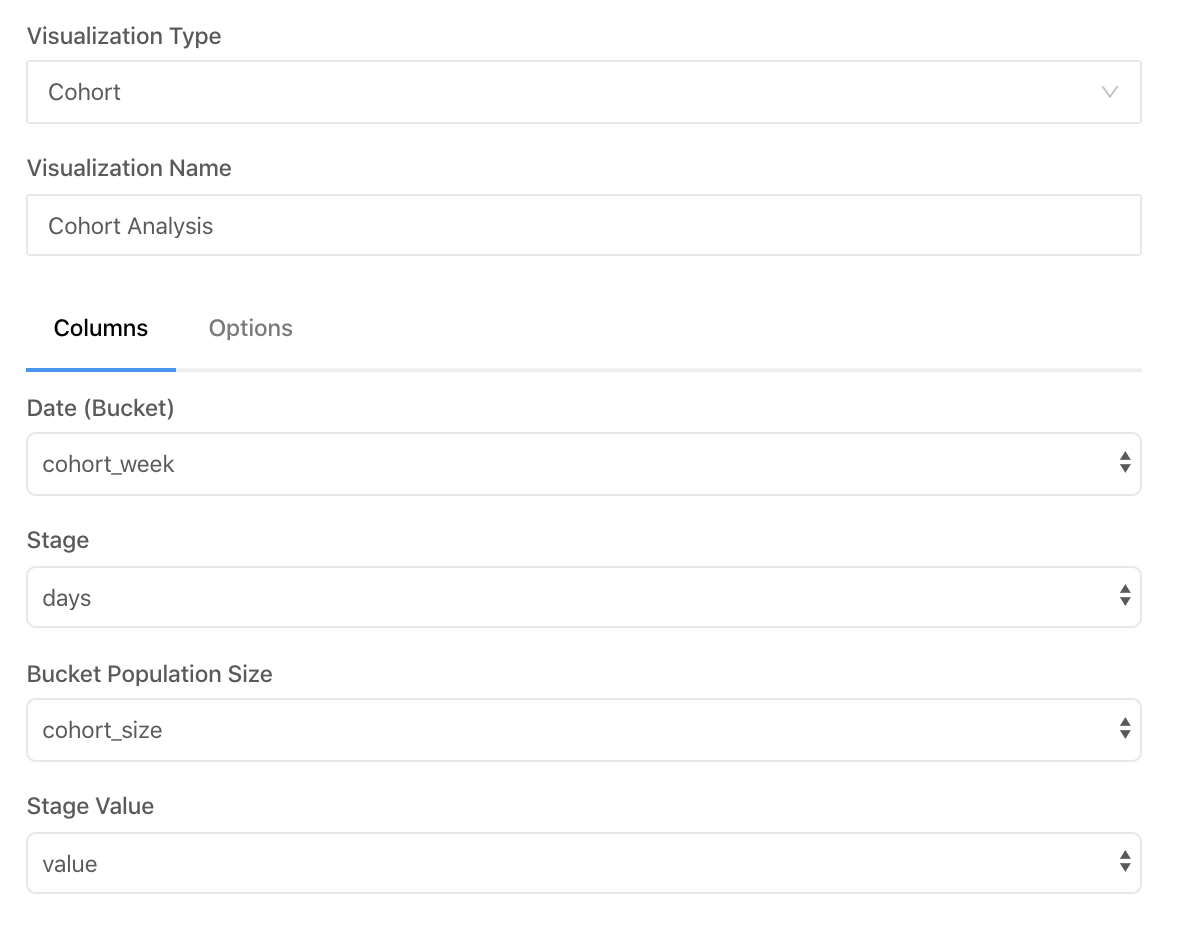
Building of Looker ML data model
In order to build a report or a dashboard in Looker, you need to provisionally set a data model. Syntax of Look ML language is quite thoroughly described in the documentation. Personally, I can just add that model description doesn’t require long-time immersion for a specialist with SQL knowledge. Rather, one needs to rearrange the approach to data model preparation. Look ML language is very much alike CSS:
Console of Look ML model creation
In the data model the following is set up: links with tables, keys, granularity, information of some fields being facts, and other – measurements. For facts, the aggregation is written. Obviously, at model creation one can use various IF / CASE expressions.
Explore mode
Probably, it’s the main killer-feature of Looker, since it allows any business departments to get data without attraction of analysts / data engineers. And, guess that’s why use of accounts with Explore mode is billed separately.
In fact, Explore mode is an interface, that allows to use the set up Look ML data model, select the required metrics and measurements and build customized report / visualization.
For example, we want to understand how many actions of any kind were performed in Looker’s interface last week. In order to do it, using Explore mode, we select Date field and apply a filter to it: last week (in this sense, Looker is quite smart and it and it will be enough writing ‘Last week’ in the filter), thereafter we choose “Category” from the measurements, and Quantity as a metric. After pressing the button Run the ready report will be generated.
Building report in Looker
Then, using the data received in the table form, you can set up the visualization of any type.
For example, Pie chart:
Applying visualization to report
Building of reports and their saving in Look
Sometimes you can have a desire to save the set of data / visualization received in Explore and share it with colleagues, for this purpose Looker has a separate essense – Look. That is ready constructed report with selected filters / measurements / facts.
Example of the saved Look
Examples of dashboards in Looker
Systemizing the warehouse of Look created, oftentimes you want to receive a ready composition / overview of key metrics, that could be displayed on one list.
For these purposes dashboard creation fits perfectly. Dashboard is created either on the wing, or using previously created Look. One of the dashboard’s “tricks” is configuration of parameters, that are changed on all the dashboard and can be applied to all the Look at the same time.
Interesting features in one line
- In Looker you can refer to other reports and, using such function, you can create a dynamic parameter, that is passed on by a link.
For example, you’ve created a report with division of revenue by countries, and in this report you can refer to the dashboard on a separate country. Following the link, a user sees the dashboard on a specific country, that he clicked on.
- On every Looker page there is a chat, where support service answers very promptly
- Looker is not able to work with data merge on the level of various DBMS, however it can combine the data on the level of ready Look (in our case, this function works really weird).
- Within the framework of work with various models, I have found out an extremely non-trivial use of SQL for calculation of unique values in a non-normalized data table, Looker calls it symmetric aggregates.
SQL, indeed, looks very non-trivial:
SELECT
order_items.order_id AS "order_items.order_id",
order_items.sale_price AS "order_items.sale_price",
(COALESCE(CAST( ( SUM(DISTINCT (CAST(FLOOR(COALESCE(users.age ,0)
*(1000000*1.0)) AS DECIMAL(38,0))) +
CAST(STRTOL(LEFT(MD5(CONVERT(VARCHAR,users.id )),15),16) AS DECIMAL(38,0))
* 1.0e8 + CAST(STRTOL(RIGHT(MD5(CONVERT(VARCHAR,users.id )),15),16) AS DECIMAL(38,0)) )
- SUM(DISTINCT CAST(STRTOL(LEFT(MD5(CONVERT(VARCHAR,users.id )),15),16) AS DECIMAL(38,0))
* 1.0e8 + CAST(STRTOL(RIGHT(MD5(CONVERT(VARCHAR,users.id )),15),16) AS DECIMAL(38,0))) )
AS DOUBLE PRECISION)
/ CAST((1000000*1.0) AS DOUBLE PRECISION), 0)
/ NULLIF(COUNT(DISTINCT CASE WHEN users.age IS NOT NULL THEN users.id
ELSE NULL END), 0)) AS "users.average_age"
FROM order_items AS order_items
LEFT JOIN users AS users ON order_items.user_id = users.id
GROUP BY 1,2
ORDER BY 3 DESC
LIMIT 500
- At implementation of Looker to a purchase, JumpStart Kit is mandatory, which costs not less than $6k. Within this kit you receive support and consultation from Looker at tool implementation.