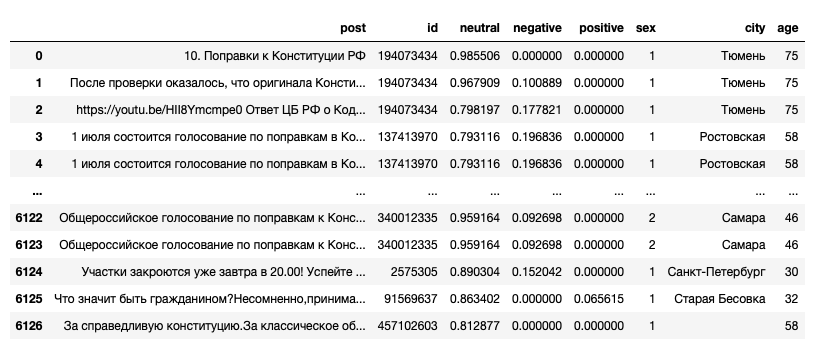
Building a scatter plot for Untappd Breweries
⏱ Время чтения текста – 7 минутToday we are going to build a scatter plot for Russian Breweries that would display the ratio between the number of reviews and their average ratings for the past 30 days. Data will be taken from check-ins left by Untappd users who rated beers. To make a plot we need markers with specified color and size. The color will depend on a brewery registration date, thus displaying it’s registration period on Untappd, while the size of a marker correlates with the range of beers represented. This article is the first part of our series dedicated to building dashboards with Plotly.
Writing a Clickhouse query
First, we need to process the data before using it in our dashboard. Here, we are using public data collected from Untappd. You can find more about this in our previous articles: “Handling website buttons in Selenium” and “Example of using dictionaries in Clickhouse with Untappd”.
from datetime import datetime, timedelta
from clickhouse_driver import Client
import plotly.graph_objects as go
import pandas as pd
import numpy as np
client = Client(host='ec1-2-34-567-89.us-east-2.compute.amazonaws.com', user='default', password='', port='9000', database='default')Our scatter plot will depend on the get_scatter_plot(n_days, top_n) function, which takes two arguments denoting a time span and a number of breweries to display. Let’s write a SQL query to calculate the Brewery Pure Average. It can be presented the following: multiply the beer rating by the total number of ratings and divide it by the number of brewery reviews. We will also pass a brewery name and its beer range to the query, these parameters can be fetched from our dictionary using the dictGet function. We are only interested in those breweries that have Brewery Pure Average > 0 and the number of reviews > 100.
brewery_pure_average = client.execute(f"""
SELECT
t1.brewery_id,
sum(t1.beer_pure_average_mult_count / t2.count_for_that_brewery) AS brewery_pure_average,
t2.count_for_that_brewery,
dictGet('breweries', 'brewery_name', toUInt64(t1.brewery_id)),
dictGet('breweries', 'beer_count', toUInt64(t1.brewery_id)),
t3.stats_age_on_service / 365
FROM
(
SELECT
beer_id,
brewery_id,
sum(rating_score) AS beer_pure_average_mult_count
FROM beer_reviews
WHERE created_at >= today()-{n_days}
GROUP BY
beer_id,
brewery_id
) AS t1
ANY LEFT JOIN
(
SELECT
brewery_id,
count(rating_score) AS count_for_that_brewery
FROM beer_reviews
WHERE created_at >= today()-{n_days}
GROUP BY brewery_id
) AS t2 ON t1.brewery_id = t2.brewery_id
ANY LEFT JOIN
(
SELECT
brewery_id,
stats_age_on_service
FROM brewery_info
) AS t3 ON t1.brewery_id = t3.brewery_id
GROUP BY
t1.brewery_id,
t2.count_for_that_brewery,
t3.stats_age_on_service
HAVING t2.count_for_that_brewery >= 150
ORDER BY brewery_pure_average
LIMIT {top_n}
""")
scatter_plot_df_with_age = pd.DataFrame(brewery_pure_average, columns=['brewery_id', 'brewery_pure_average', 'rating_count', 'brewery_name', 'beer_count'])Working with a DataFrame
Add two dotted lines that will pass through the median values of each axis. That way we can find out which breweries are above average, the best ones will be in the upper right area.
dict_list = []
dict_list.append(dict(type="line",
line=dict(
color="#666666",
dash="dot"),
x0=0,
y0=np.median(scatter_plot_df_with_age.brewery_pure_average),
x1=7000,
y1=np.median(scatter_plot_df_with_age.brewery_pure_average),
line_width=1,
layer="below"))
dict_list.append(dict(type="line",
line=dict(
color="#666666",
dash="dot"),
x0=np.median(scatter_plot_df_with_age.rating_count),
y0=0,
x1=np.median(scatter_plot_df_with_age.rating_count),
y1=5,
line_width=1,
layer="below"))Add annotations to display median values by hovering:
annotations_list = []
annotations_list.append(
dict(
x=8000,
y=np.median(scatter_plot_df_with_age.brewery_pure_average) - 0.1,
xref="x",
yref="y",
text=f"Median value: {round(np.median(scatter_plot_df_with_age.brewery_pure_average), 2)}",
showarrow=False,
font={
'family':'Roboto, light',
'color':'#666666',
'size':12
}
)
)
annotations_list.append(
dict(
x=np.median(scatter_plot_df_with_age.rating_count) + 180,
y=0.8,
xref="x",
yref="y",
text=f"Median value: {round(np.median(scatter_plot_df_with_age.rating_count), 2)}",
showarrow=False,
font={
'family':'Roboto, light',
'color':'#666666',
'size':12
},
textangle=-90
)
)Let’s make our plot more informative by splitting breweries into 4 groups according to the beer range. The first group will include breweries with less than 10 brands, the second group for those holding 10-30 brands, the third one for 30-50 brands, and the last one for large breweries with >50 brands. We stored marker sizes in the bucket_beer_count list.
bucket_beer_count = []
for beer_count in scatter_plot_df_with_age.beer_count:
if beer_count < 10:
bucket_beer_count.append(7)
elif 10 <= beer_count <= 30:
bucket_beer_count.append(9)
elif 31 <= beer_count <= 50:
bucket_beer_count.append(11)
else:
bucket_beer_count.append(13)
scatter_plot_df_with_age['bucket_beer_count'] = bucket_beer_countNext step is to perform age-based splitting
bucket_age = []
for age in scatter_plot_df_with_age.age_on_service:
if age < 4:
bucket_age.append(0)
elif 4 <= age <= 6:
bucket_age.append(1)
elif 6 < age < 8:
bucket_age.append(2)
else:
bucket_age.append(3)
scatter_plot_df_with_age['bucket_age'] = bucket_ageLet’s divide our DataFrame into 4 parts to build separate scatter plots with its own color and size.
scatter_plot_df_0 = scatter_plot_df[scatter_plot_df.bucket == 0]
scatter_plot_df_1 = scatter_plot_df[scatter_plot_df.bucket == 1]
scatter_plot_df_2 = scatter_plot_df[scatter_plot_df.bucket == 2]
scatter_plot_df_3 = scatter_plot_df[scatter_plot_df.bucket == 3]Plotting
Now we are ready to build the plot, add our 4 brewery groups one by one, setting its key parameters: name, marker color, annotation transparency and text.
fig = go.Figure()
fig.add_trace(go.Scatter(
x=scatter_plot_df_0.rating_count,
y=scatter_plot_df_0.brewery_pure_average,
name='< 4',
mode='markers',
opacity=0.85,
text=scatter_plot_df_0.name_count,
marker_color='rgb(114, 183, 178)',
marker_size=scatter_plot_df_0.bucket_beer_count,
textfont={"family":"Roboto, light",
"color":"black"
}
))
fig.add_trace(go.Scatter(
x=scatter_plot_df_1.rating_count,
y=scatter_plot_df_1.brewery_pure_average,
name='4 – 6',
mode='markers',
opacity=0.85,
marker_color='rgb(76, 120, 168)',
text=scatter_plot_df_1.name_count,
marker_size=scatter_plot_df_1.bucket_beer_count,
textfont={"family":"Roboto, light",
"color":"black"
}
))
fig.add_trace(go.Scatter(
x=scatter_plot_df_2.rating_count,
y=scatter_plot_df_2.brewery_pure_average,
name='6 – 8',
mode='markers',
opacity=0.85,
marker_color='rgb(245, 133, 23)',
text=scatter_plot_df_2.name_count,
marker_size=scatter_plot_df_2.bucket_beer_count,
textfont={"family":"Roboto, light",
"color":"black"
}
))
fig.add_trace(go.Scatter(
x=scatter_plot_df_3.rating_count,
y=scatter_plot_df_3.brewery_pure_average,
name='8+',
mode='markers',
opacity=0.85,
marker_color='rgb(228, 87, 86)',
text=scatter_plot_df_3.name_count,
marker_size=scatter_plot_df_3.bucket_beer_count,
textfont={"family":"Roboto, light",
"color":"black"
}
))
fig.update_layout(
title=f"The ratio between the number of reviews and the average brewery rating for the past <br> {n_days} days, top {top_n} breweries",
font={
'family':'Roboto, light',
'color':'black',
'size':14
},
plot_bgcolor='rgba(0,0,0,0)',
yaxis_title="Average rating",
xaxis_title="Number of reviews",
legend_title_text='Registration period<br> on Untappd in years:',
height=750,
shapes=dict_list,
annotations=annotations_list
)Voila, the scatter plot is done! Each point is a separate brewery. The color shows the brewery beer range and when hovering we will see a summary including the average rating for the past 30 days, number of reviews, brewery name, and beer range. The dotted lines are passing through the median values we calculated with NumPy, they’re showing us the best breweries in the upper right. In our next article, we are going to create a breweries dashboard with dynamic parameters.