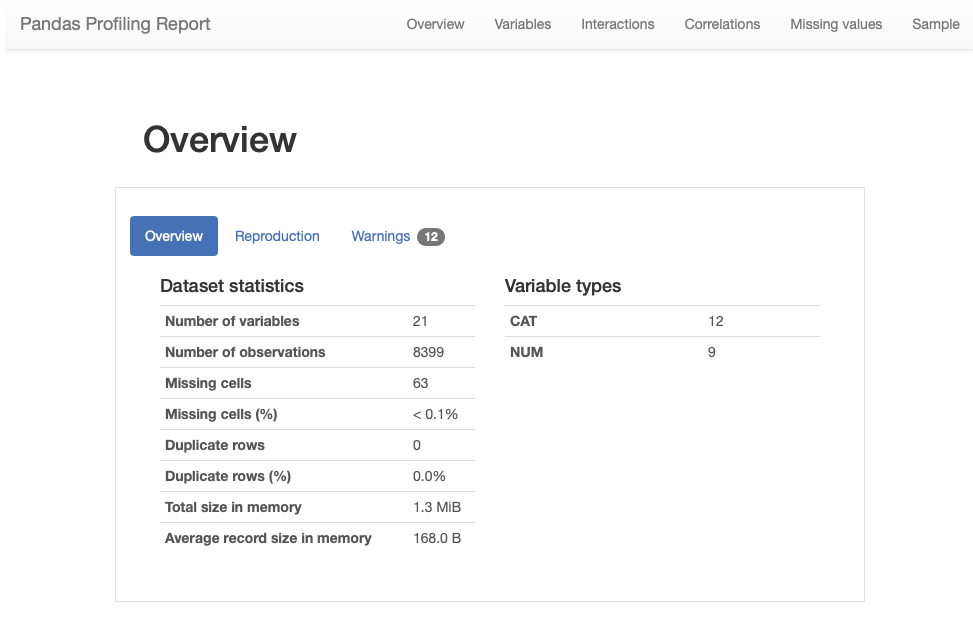
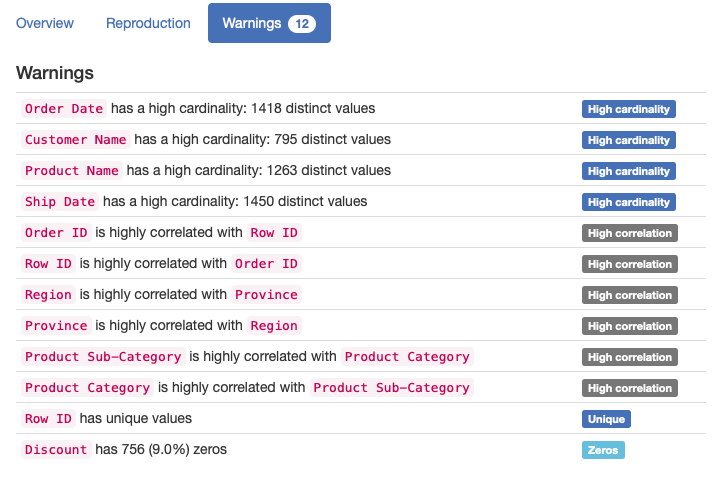
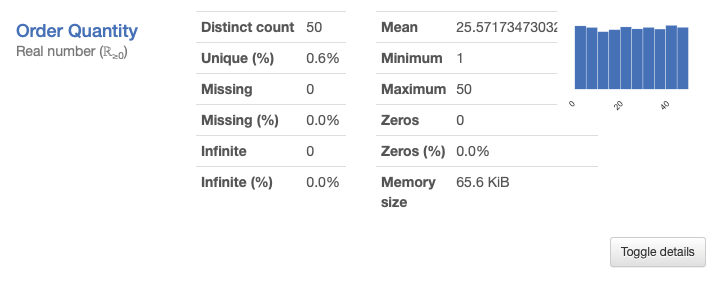
Python and lyrics of Zemfira’s new album: capturing the spirit of her songs
⏱ Время чтения текста – 16 минут
Zemfira’s latest studio album, Borderline, was released in February, 8 years after the previous one. For this album, various people cooperated with her, including her relatives – the riff for the song “Таблетки” was written by her nephew from London. The album turned out to be diverse: for instance, the song “Остин” is dedicated to the main character of the Homescapes game by the Russian studio Playrix (by the way, check out the latest Business Secrets with the Bukhman brothers, they also mention it there). Zemfira liked the game a lot, thus, she contacted Playrix to create this song. Also, the song “Крым” was written as a soundtrack to a new film by Zemfira’s colleague Renata Litvinova.
Listen new album in Apple Music / Яндекс.Музыке / Spotify
Nevertheless, the spirit of the whole album is rather gloomy – the songs often repeat the words ‘боль’, ‘ад’, ‘бесишь’ and other synonyms. We decided to conduct an exploratory analysis of her album, and then, using the Word2Vec model and a cosine measure, look at the semantic closeness of the songs and calculate the general mood of the album.
For those who are bored with reading about data preparation and analysis steps, you can go directly to the results.
Data preparation
For starters, we write a data processing script. The purpose of the script is to collect a united csv-table from a set of text files, each of which contains a song. At the same time, we have to get rid of all punctuation marks and unnecessary words as we need to focus only on significant content.
import pandas as pd
import re
import string
import pymorphy2
from nltk.corpus import stopwordsThen we create a morphological analyzer and expand the list of everything that needs to be discarded:
morph = pymorphy2.MorphAnalyzer()
stopwords_list = stopwords.words('russian')
stopwords_list.extend(['куплет', 'это', 'я', 'мы', 'ты', 'припев', 'аутро', 'предприпев', 'lyrics', '1', '2', '3', 'то'])
string.punctuation += '—'The names of the songs are given in English, so we have to create a dictionary for translation into Russian and a dictionary, from which we will later make a table:
result_dict = dict()
songs_dict = {
'snow':'снег идёт',
'crimea':'крым',
'mother':'мама',
'ostin':'остин',
'abuse':'абьюз',
'wait_for_me':'жди меня',
'tom':'том',
'come_on':'камон',
'coat':'пальто',
'this_summer':'этим летом',
'ok':'ок',
'pills':'таблетки'
}Let’s define several necessary functions. The first one reads the entire song from the file and removes line breaks, the second clears the text from unnecessary characters and words, and the third one converts the words to normal form, using the pymorphy2 morphological analyzer. The pymorphy2 module does not always handle ambiguity well – additional processing is required for the words ‘ад’ and ‘рай’.
def read_song(filename):
f = open(f'{filename}.txt', 'r').read()
f = f.replace('\n', ' ')
return f
def clean_string(text):
text = re.split(' |:|\.|\(|\)|,|"|;|/|\n|\t|-|\?|\[|\]|!', text)
text = ' '.join([word for word in text if word not in string.punctuation])
text = text.lower()
text = ' '.join([word for word in text.split() if word not in stopwords_list])
return text
def string_to_normal_form(string):
string_lst = string.split()
for i in range(len(string_lst)):
string_lst[i] = morph.parse(string_lst[i])[0].normal_form
if (string_lst[i] == 'аду'):
string_lst[i] = 'ад'
if (string_lst[i] == 'рая'):
string_lst[i] = 'рай'
string = ' '.join(string_lst)
return stringAfter all this preparation, we can get back to the data and process each song and read the file with the corresponding name:
name_list = []
text_list = []
for song, name in songs_dict.items():
text = string_to_normal_form(clean_string(read_song(song)))
name_list.append(name)
text_list.append(text)Then we combine everything into a DataFrame and save it as a csv-file.
df = pd.DataFrame()
df['name'] = name_list
df['text'] = text_list
df['time'] = [290, 220, 187, 270, 330, 196, 207, 188, 269, 189, 245, 244]
df.to_csv('borderline.csv', index=False)Result:

Word cloud for the whole album
To begin with the analysis, we have to construct a word cloud, because it can display the most common words found in these songs. We import the required libraries, read the csv-file and set the configurations:
import nltk
from wordcloud import WordCloud
import pandas as pd
import matplotlib.pyplot as plt
from nltk import word_tokenize, ngrams
%matplotlib inline
nltk.download('punkt')
df = pd.read_csv('borderline.csv')Now we create a new figure, set the design parameters and, using the word cloud library, display words with the size directly proportional to the frequency of the word. We additionally indicate the name of the song above the corresponding graph.
fig = plt.figure()
fig.patch.set_facecolor('white')
plt.subplots_adjust(wspace=0.3, hspace=0.2)
i = 1
for name, text in zip(df.name, df.text):
tokens = word_tokenize(text)
text_raw = " ".join(tokens)
wordcloud = WordCloud(colormap='PuBu', background_color='white', contour_width=10).generate(text_raw)
plt.subplot(4, 3, i, label=name,frame_on=True)
plt.tick_params(labelsize=10)
plt.imshow(wordcloud)
plt.axis("off")
plt.title(name,fontdict={'fontsize':7,'color':'grey'},y=0.93)
plt.tick_params(labelsize=10)
i += 1
EDA of the lyrics
Let us move to the next part and analyze the lyrics. To do this, we have to import special libraries to deal with data and visualization:
import plotly.graph_objects as go
import plotly.figure_factory as ff
from scipy import spatial
import collections
import pymorphy2
import gensim
morph = pymorphy2.MorphAnalyzer()Firstly, we should count the overall number of words in each song, the number of unique words, and their percentage:
songs = []
total = []
uniq = []
percent = []
for song, text in zip(df.name, df.text):
songs.append(song)
total.append(len(text.split()))
uniq.append(len(set(text.split())))
percent.append(round(len(set(text.split())) / len(text.split()), 2) * 100)All this information should be written in a DataFrame and additionally we want to count the number of words per minute for each song:
df_words = pd.DataFrame()
df_words['song'] = songs
df_words['total words'] = total
df_words['uniq words'] = uniq
df_words['percent'] = percent
df_words['time'] = df['time']
df_words['words per minute'] = round(total / (df['time'] // 60))
df_words = df_words[::-1]
It would be great to visualize the data, so let us build two bar charts: one for the number of words in the song, and the other one for the number of words per minute.
colors_1 = ['rgba(101,181,205,255)'] * 12
colors_2 = ['rgba(62,142,231,255)'] * 12
fig = go.Figure(data=[
go.Bar(name='📝 Total number of words,
text=df_words['total words'],
textposition='auto',
x=df_words.song,
y=df_words['total words'],
marker_color=colors_1,
marker=dict(line=dict(width=0)),),
go.Bar(name='🌀 Unique words',
text=df_words['uniq words'].astype(str) + '<br>'+ df_words.percent.astype(int).astype(str) + '%' ,
textposition='inside',
x=df_words.song,
y=df_words['uniq words'],
textfont_color='white',
marker_color=colors_2,
marker=dict(line=dict(width=0)),),
])
fig.update_layout(barmode='group')
fig.update_layout(
title =
{'text':'<b>The ratio of the number of unique words to the total</b><br><span style="color:#666666"></span>'},
showlegend = True,
height=650,
font={
'family':'Open Sans, light',
'color':'black',
'size':14
},
plot_bgcolor='rgba(0,0,0,0)',
)
fig.update_layout(legend=dict(
yanchor="top",
xanchor="right",
))
fig.show()colors_1 = ['rgba(101,181,205,255)'] * 12
colors_2 = ['rgba(238,85,59,255)'] * 12
fig = go.Figure(data=[
go.Bar(name='⏱️ Track length, min.',
text=round(df_words['time'] / 60, 1),
textposition='auto',
x=df_words.song,
y=-df_words['time'] // 60,
marker_color=colors_1,
marker=dict(line=dict(width=0)),
),
go.Bar(name='🔄 Words per minute',
text=df_words['words per minute'],
textposition='auto',
x=df_words.song,
y=df_words['words per minute'],
marker_color=colors_2,
textfont_color='white',
marker=dict(line=dict(width=0)),
),
])
fig.update_layout(barmode='overlay')
fig.update_layout(
title =
{'text':'<b>Track length and words per minute</b><br><span style="color:#666666"></span>'},
showlegend = True,
height=650,
font={
'family':'Open Sans, light',
'color':'black',
'size':14
},
plot_bgcolor='rgba(0,0,0,0)'
)
fig.show()Working with Word2Vec model
Using the gensim module, load the model pointing to a binary file:
model = gensim.models.KeyedVectors.load_word2vec_format('model.bin', binary=True)Для материала мы использовали готовую обученную на Национальном Корпусе Русского Языка модель от сообщества RusVectōrēs
The Word2Vec model is based on neural networks and allows you to represent words in the form of vectors, taking into account the semantic component. It means that if we take two words – for instance, “mom” and “dad”, then represent them as two vectors and calculate the cosine, the values will be close to 1. Similarly, two words that have nothing in common in their meaning have a cosine measure close to 0.
Now we will define the get_vector function: it will take a list of words, recognize a part of speech for each word, and then receive and summarize vectors, so that we can find vectors even for whole sentences and texts.
def get_vector(word_list):
vector = 0
for word in word_list:
pos = morph.parse(word)[0].tag.POS
if pos == 'INFN':
pos = 'VERB'
if pos in ['ADJF', 'PRCL', 'ADVB', 'NPRO']:
pos = 'NOUN'
if word and pos:
try:
word_pos = word + '_' + pos
this_vector = model.word_vec(word_pos)
vector += this_vector
except KeyError:
continue
return vectorFor each song, find a vector and select the corresponding column in the DataFrame:
vec_list = []
for word in df['text']:
vec_list.append(get_vector(word.split()))
df['vector'] = vec_listSo, now we should compare these vectors with one another, calculating their cosine proximity. Those songs with a cosine metric higher than 0.5 will be saved separately – this way we will get the closest pairs of songs. We will write the information about the comparison of vectors into the two-dimensional list result.
similar = dict()
result = []
for song_1, vector_1 in zip(df.name, df.vector):
sub_list = []
for song_2, vector_2 in zip(df.name.iloc[::-1], df.vector.iloc[::-1]):
res = 1 - spatial.distance.cosine(vector_1, vector_2)
if res > 0.5 and song_1 != song_2 and (song_1 + ' / ' + song_2 not in similar.keys() and song_2 + ' / ' + song_1 not in similar.keys()):
similar[song_1 + ' / ' + song_2] = round(res, 2)
sub_list.append(round(res, 2))
result.append(sub_list)Moreover, we can construct the same bar chart:
df_top_sim = pd.DataFrame()
df_top_sim['name'] = list(similar.keys())
df_top_sim['value'] = list(similar.values())
df_top_sim.sort_values(by='value', ascending=False)И построим такой же bar chart:
colors = ['rgba(101,181,205,255)'] * 5
fig = go.Figure([go.Bar(x=df_top_sim['name'],
y=df_top_sim['value'],
marker_color=colors,
width=[0.4,0.4,0.4,0.4,0.4],
text=df_top_sim['value'],
textfont_color='white',
textposition='auto')])
fig.update_layout(
title =
{'text':'<b>Топ-5 closest songs</b><br><span style="color:#666666"></span>'},
showlegend = False,
height=650,
font={
'family':'Open Sans, light',
'color':'black',
'size':14
},
plot_bgcolor='rgba(0,0,0,0)',
xaxis={'categoryorder':'total descending'}
)
fig.show()Given the vector of each song, let us calculate the vector of the entire album – add the vectors of the songs. Then, for such a vector, using the model, we get the words that are the closest in spirit and meaning.
def get_word_from_tlist(lst):
for word in lst:
word = word[0].split('_')[0]
print(word, end=' ')
vec_sum = 0
for vec in df.vector:
vec_sum += vec
sim_word = model.similar_by_vector(vec_sum)
get_word_from_tlist(sim_word)небо тоска тьма пламень плакать горе печаль сердце солнце мрак
This is probably the key result and the description of Zemfira’s album in just 10 words.
Finally, we build a general heat map, each cell of which is the result of comparing the texts of two tracks with a cosine measure.
colorscale=[[0.0, "rgba(255,255,255,255)"],
[0.1, "rgba(229,232,237,255)"],
[0.2, "rgba(216,222,232,255)"],
[0.3, "rgba(205,214,228,255)"],
[0.4, "rgba(182,195,218,255)"],
[0.5, "rgba(159,178,209,255)"],
[0.6, "rgba(137,161,200,255)"],
[0.7, "rgba(107,137,188,255)"],
[0.8, "rgba(96,129,184,255)"],
[1.0, "rgba(76,114,176,255)"]]
font_colors = ['black']
x = list(df.name.iloc[::-1])
y = list(df.name)
fig = ff.create_annotated_heatmap(result, x=x, y=y, colorscale=colorscale, font_colors=font_colors)
fig.show()Results and data interpretation
To give valuable conclusions, we would like to take another look at everything we got. First of all, let us focus on the word cloud. It is easy to see that the words ‘боль’, ‘невозможно’, ‘сорваться’, ‘растерзаны’, ‘сложно’, ‘терпеть’, ‘любить’ have a very decent size, because such words are often found throughout the entire lyrics:
Давайте ещё раз посмотрим на всё, что у нас получилось — начнём с облака слов. Нетрудно заметить, что у слов «боль», «невозможно», «сорваться», «растерзаны», «сложно», «терпеть», «любить» размер весьма приличный — всё потому, что такие слова встречаются часто на протяжении всего текста песен:

The song “Крым” turned out to be one of the most diverse songs – it contains 74% of unique words. Also, the song “Снег идет” contains very few words, so the majority, which is 82%, are unique. The largest song on the album in terms of amount of words is the track “Таблетки” – there are about 150 words in total.
As it was shown on the last chart, the most dynamic track is “Таблетки”, as much as 37 words per minute – nearly one word for every two seconds – and the longest track is “Абьюз”, and according to the previous chart, it also has the lowest percentage of unique words – 46%.
Top 5 most semantically similar text pairs:
We also got the vector of the entire album and found the closest words. Just take a look at them – ‘тьма’, ‘тоска’, ‘плакать’, ‘горе’, ‘печаль’, ‘сердце’ – this is the list of words that characterizes Zemfira’s lyrics!
небо тоска тьма пламень плакать горе печаль сердце солнце мрак
The final result is a heat map. From the visualization, it is noticeable that almost all songs are quite similar to each other – the cosine measure for many pairs exceeds the value of 0.4.
Conclusions
In the material, we carried out an EDA of the entire text of the new album and, using the pre-trained Word2Vec model, we proved the hypothesis – most of the “Borderline” songs are permeated with rather dark lyrics. However, this is normal, because we love Zemfira precisely for her sincerity and straightforwardness.